
Forest of Pages
The PDF format has established itself as the standard for document exchange. There are many programs under Linux that you can use to take advantage of all of the possibilities PDFs offer.
|

Welcomia, 123RF
The PDF format has established itself as the standard for document exchange. There are many programs under Linux that you can use to take advantage of all of the possibilities PDFs offer.
Documents that are completely different from one another, like billing statements, books, scholarly works, and more, are regularly composed, transferred, and distributed with digital tools. Preferably, these transfers are made with the platform-independent PDF format. Documents that are searchable make it easy to quickly find a particular item inside of a file. Metadata contains additional information.
In addition to all these advantages, there are countless possibilities for working on PDF documents. As a means of fulfilling specific needs, you can do things like remove individual pages, add new ones, or take individual pages and add them to a new PDF file. You can also highlight passages, draw arrows and circles around text, and add comments to a PDF file, just as you would with a printed text.
In order to fully exploit all of the PDF format's possibilities, the file should be searchable. This feature lets you browse through several PDF files for particular words, as well as use the search function on the PDF viewer to quickly find the correct passage inside of the file. Typically, you can search through files created using LaTeX and LibreOffice. The situation looks different though with PDF files created from scans. Once scanned, the files consist purely of image data. A text recognition program lets you add a text layer to the data.
A good text recognition program to use with Linux is the optical character recognition (OCR) engine Tesseract [1]. Most distributions have the program in their package sources. You will find it in the tesseract-ocr package in Debian and Ubuntu. In addition, you will need a package with the languages that the program is supposed to recognize. For English, use tesseract-ocr-eng . If you install tesseract-ocr-all , you'll install all language packages. Be aware this is a hefty install.
The program itself does not have a graphical interface. However, the contents of an image file can be translated completely into machine readable text via the command line. Listing 1 shows all of the languages that are available. The osd found in Listing 1 stands for "Orientation and Script Detection," which refers to automatic detection of the scan orientation and text recognition in columns. You should let Tesseract take a scan, such as a example.jpg , and have the recognized text appear as a text file of the same name.
Listing 1
Tesseract languages
$ tesseract --list-langs List of available languages (3): deu eng osd $ tesseract -l eng image.jpg image
Now you should have a searchable text file (called image.txt if you followed the example) on your hard drive. The PDF itself continues to recognize only image data. Applications like OCRmyPDF [2] go one step further and embed the text found using the Tesseract OCR engine directly into the PDF. You can do something similar with LibreOffice Export.
The program can be installed under Debian Testing from the package sources. In Ubuntu, you can install it using:
sudo apt install ocrmypdf
If the version provided by your package manager is outdated, you can use the package management program Pip. You can use this program to install the Python package manager together with all of the dependencies for OCRmyPDF, update Pip, and then install the program (Listing 2).
Listing 2
Install Pip and OCRmyPDF
$ sudo apt install python3-pip python3-pil python3-pytest python3-reportlab zlib1g-dev libjpeg-dev libffi-dev ghostscript qpdf unpaper $ sudo pip3 install --upgrade pip $ sudo pip3 install ocrmypdf
In order to create a searchable PDF file from a scan, you should use the commands from Listing 3. Since Tesseract text recognition analyzes not just letter by letter but also by comparison with a language-specific dictionary, you will need to specify the correct language when calling. When no language is specified, Tesseract defaults to English.
Listing 3
Create a searchable PDF
$ ocrmypdf -l eng article.pdf article_ocr.pdf $ ocrmypdf -l en -c -d -i --title "Sherlock Holmes: A Scandal in Bohemia" --author "Arthur Conan Doyle" --subject Scan --keywords "Crime, Short story" scan.pdf scan_ocr.pdf
Both of the options -c and -d prompt OCRmyPDF to correct scanning errors, such as dark bars. They also straighten crooked text. In order to accomplish this, OCRmyPDF uses Unpaper [3], a tool that has been optimized for this purpose. Unless you indicate otherwise, OCRmyPDF only uses the pages that have been corrected by Unpaper for internal text recognition. The option -i also puts the cleaned up scans in the output file.
Calling Unpaper as a cleanup expert primarily works well when the scan consists only of continuous text. If there are also images and graphical elements in the scanned document, then it is entirely possible that Unpaper will also see these as scanning errors and delete them. If in doubt, it is a good idea to avoid this option.
To finish, you should define metadata, such as the title, author, subject, and keywords, for the resulting PDF document. Enter individual words behind the corresponding switch. Several words strung together or an entire sentence should be put in quotation marks. The name of the input file is found at the end, followed by the name of the output file. The final result is a searchable PDF file.
You can get to the desired passage in a searchable PDF file using the integrated search function in the PDF viewer. If you would like to look through multiple PDF files for specific phrases, you should use the program Pdfgrep [4]. Commonly used distributions usually list this program under the same name in their package sources. In Ubuntu, you can use:
sudo apt instal pdfgrep
to install it.
If for example, you want to find all of your scanned bills from 2016, then you would use the following command:
$ pdfgrep -i -n ,invoice|2016' *.pdf
The option -i lets Pdfgrep ignore the difference between capital and lowercase letters during a search, so Pdfgrep will return "Invoice," "invoice," INVOICE," and even "iNvOice." The option -n provides the specific page in the PDF file for each item found (Figure 1).
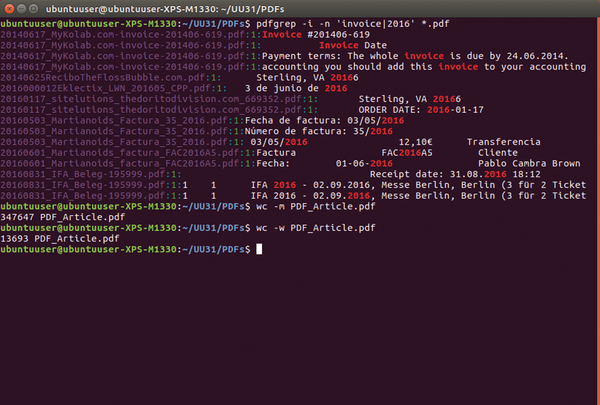 Figure 1: Using Pdfgrep lets you search through the contents of PDF files from the command line. The command wc helps you achieve the correct text length when you are writing an article.
Figure 1: Using Pdfgrep lets you search through the contents of PDF files from the command line. The command wc helps you achieve the correct text length when you are writing an article.
Author guidelines for magazines or for final papers written in an academic setting often include rules about minimal and maximum word or character count. These values are easy to determine when you use OCRmyPDF and issue the command wc (Listing 4). In Debian and Ubuntu, this is found in the coreutils package and often comes preinstalled. Replace the -m option (count characters) with -w to get the command to output the word count.
Listing 4
Using wc to count words
$ wc -m masters thesis.pdf 302605 masters thesis.pdf $ wc -w masters thesis.pdf 13385 masters thesis.pdf
Pages: 8
US / Canada
UK / Australia

With a small script, you can convert large amounts of scanned text into PDF files that you can then browse with typical Linux tools – all thanks to OCR.

Paperwork is a new attempt to create the paperless office using free software components. This article describes just how far it's come.

Faulty unmounts can quickly lead to disaster with SD cards and USB sticks. Magic Rescue can get your data back.

If you want not only to enjoy e-books in EPUB format but also to create them, take a look at the easy-to-use and versatile editor from Sigil.

Finding weak points and problematic configurations in an intranet typically takes a lot of time and effort. Thanks to careful integration into Kali Linux, the OpenVAS and Nmap tools can be genuinely helpful.