Web Spy
The ultra-slim web server HTTPie turns out to be an elegant synthesis of curl and wget, making it ideal for use with pipes.

Andrea De Martin, 123RF
The ultra-slim web server HTTPie turns out to be an elegant synthesis of curl and wget, making it ideal for use with pipes.
HTTPie has many features of wget and curl , allowing various types of data transfer. It's also suitable for tasks such as detailed website analysis. Output can be redirected to a file, and file inputs are also possible. This makes HTTPie [1] ideal for use with pipes.
On Ubuntu, you can install HTTPie using apt :
sudo apt install httpie
or grabbing the latest version of the source code from the GitHub repository [2].
Call HTTPie using the command:
http <options> <method> <URL>
If you don't specify any options, you'll just see the website's code (Figure 1).
 Figure 1: You can call a web page without any additional options.
Figure 1: You can call a web page without any additional options.
Table 1 lists some of HTTPie's the most useful options, while Table 2 lists important access methods to HTTP servers.
Table 1
Options
| Action | Option | Note |
|---|---|---|
| Specify the output scope | --print HBhb | H (request header), B (request body), h (reply header), B (reply body) |
| "Complete output" for pipe and output redirection | -v | – |
| Download | -d [URL] | Alternatively: --download |
| Assign name to a download | -o [FILENAME] | Default: Original name |
| Resume interrupted download | -c | – |
| Specify user name | -a [USERNAME] | – |
One pitfall when outputting web pages is that http detects whether output is redirected or given to a pipe. With standard usage, you'll find yourself frustrated at every turn:
http <IP> / <name> <file>
simply does not work.
To resolve this, you need to use the -v or --print options along with the command. You can use the option shown in Listing 1 and Figure 2 for instance. In this example, the web server was also prompted to list available HTTP methods (again refer to Table 2).
Listing 1
query.sh
#!/bin/bash # Example 1 Querying a Web Page http --print Hh $1 echo "-------------------------------------------------" # Example 2 Query HTTP methods, for the next- # Processing, the -v option is required: echo -n "Possible HTTP methods: " http -v options $1 | grep Allow | cut -d: -f2 echo "-------------------------------------------------"
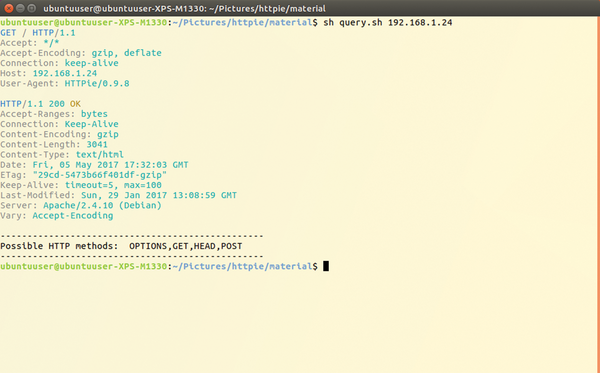 Figure 2: Output of web pages and further processing.
Figure 2: Output of web pages and further processing.
Table 2
Most Useful HTTP methods
| Command | Function |
|---|---|
| get | Request contents of a web server (default) |
| head | Request web page headers. |
| trace | Output the request as it arrives at the requested web server |
| options | Lists the HTTP methods allowed on the requested web server |
| post | Send data to the web server (e.g., in the form field = value ) |
| put | Send a file to the web server |
Use the --print HhBb option to narrow down what HTTPie shows, and see what you send and receive. You can use this for shell scripts. Listing 1 uses this technique. Figure 3 shows the output of two requests sent to the same web server. The first shows the request header (--print H ); the second shows the reply header (--print h ).
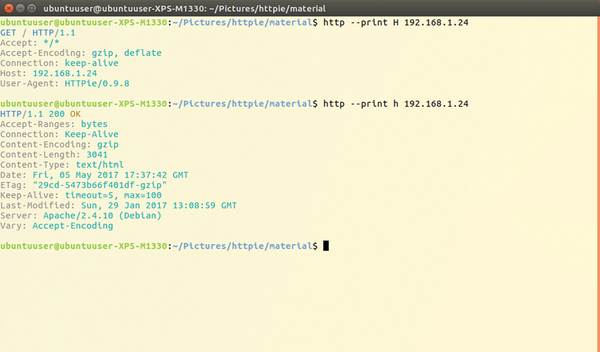 Figure 3: Use the option --print to capture different parts of the back and forth with the server.
Figure 3: Use the option --print to capture different parts of the back and forth with the server.
If you want to check the HTTP status codes, use the following command
http --print h 192.168.0.83 | grep "HTTP" | cut -d" " -f3
in the shell script. Note the blank character used as a field separator for the cut command.
If you look at the first line of the second example's output in Figure 3, you can probably figure out what the line will return: OK .
You can use the -d option to download files. Figure 4 shows the output of this command. You'll see the download progress in the terminal. The header details are interesting. They recognize the type of payload, as well as the size and date of the last process.
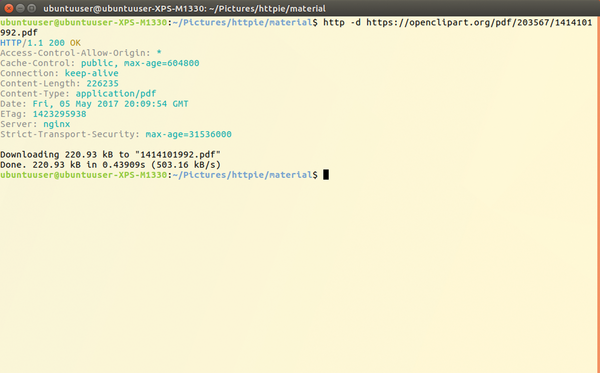 Figure 4: Downloading a file with HTTPie.
Figure 4: Downloading a file with HTTPie.
You can resume interrupted downloads without restarting, as long as the server has been configured to handle partial content. To do this, assign your own filename to the download (-o FILENAME ) and also set the -c option. The full command, in the right order, would look something like this:
http -dco unicorn.pdf https://openclipart.org/pdf/203567/1414101992.pdf
The option -a also allows you to connect to Web Distributed Authoring and Versioning (WebDAV) services and download files. Figure 5 shows how to get started. For example, using the -v option, you can use the get request with a resource.
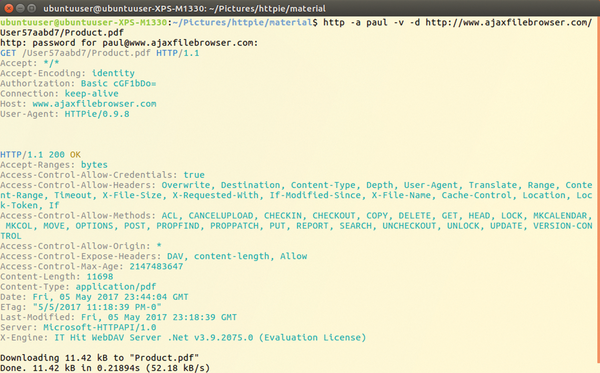 Figure 5: Download a file from a WebDAV resource.
Figure 5: Download a file from a WebDAV resource.
Download the contents of a WebDAV directory into your working directory using -d , and examine it in a browser, such as w3m . Naturally, you can parse the output through pipes instead and then, for instance, start to download very specific data.
Deletion is performed using the HTTP method delete . You must specify the complete resource, so wildcard characters won't work. In Figure 6, you can see http with delete in action.
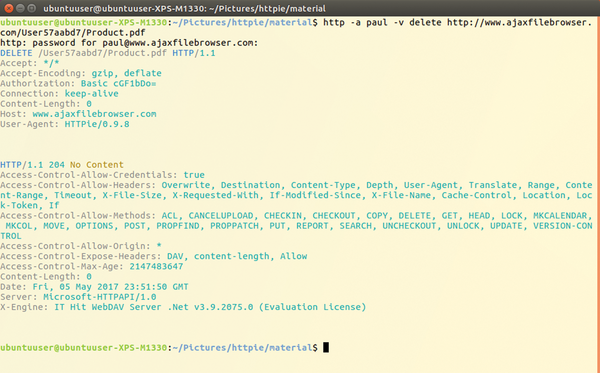 Figure 6: Deleting a file in the WebDAV directory.
Figure 6: Deleting a file in the WebDAV directory.
This is not a tool for homemade Internet surveillance. However, you can access device controls via a web interface or even pages with defined values, and so on. Often these have no mail interface, so you would have to access the web page at irregular intervals.
The shell script in Listing 2 monitors the contents of a simple web page (like what you can see in Listing 3). If the keyword "empty" appears, everything is fine. A mail for this is only sent when the script is started or after an error has been reported and then amended. If something changes, then an error message is sent. The target mailbox is not flooded with identical error messages thanks to a flag that keeps track of when changes occur.
Listing 2
control.sh
#!/bin/bash
# Usage: control.sh <site URL> <user to email>
# Variable to accept the exit code
l=0
# Variable that memorizes the previous state
flag=1
while true; do
http -v $1 | grep "empty"> /dev/null
l=$(echo $?)
if [ $l -eq 0 ]; then
if [ $flag -eq 1 ]; then
echo "Message: empty" | mail -s "Normal Message" $2
# Reset $flag to "Normal"
flag=0
fi
else
if [ $flag -eq 0 ]; then
echo "Message: error" | mail -s "ERROR MESSAGE" $2
# Set $flag to "Error"
flag=1
fi
fi
sleep 10
done
Listing 3
testsite.html
<html> <body> <h1>Test Site</h1> <p>192.169.124 Test field<p> <p>(Keyword: empty)<p> </body> </html>
The script takes two parameters: the URL of the webpage you want to monitor, and the user to whom you want to send the warning emails. Running the script would look like this:
control.sh www.somesite.com/test.html <user>
For all of this to work, you will have to install the mailutils package:
sudo apt install mailutils
Choose Internal only from the options the installer gives you, and then set up mail to work with your user. You do this by first making your user join the the mail group:
sudo usermod -a -G mail <user>
Next you have to create an email box for user by sending an internal email to the user. You can do this as root with:
sudo mail -s "First email" <user>
You can see the internal emails you receive by simply running mail .
Figure 7 shows what happens during a test run: new emails show up in you mailing list. Figure 8 (top) shows the sample page, which was altered (bottom) for demonstration purposes while the script was running.
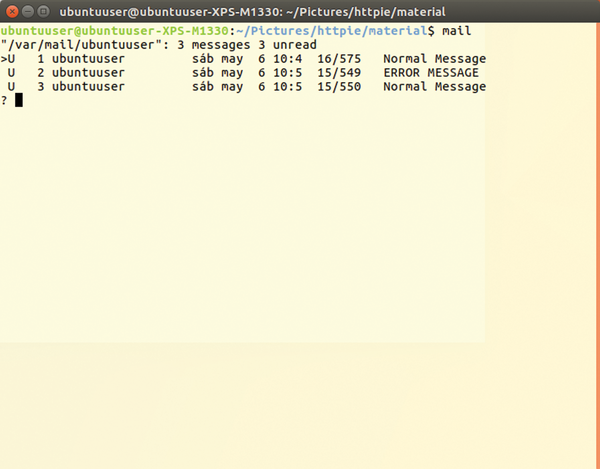 Figure 7: Overview of the status emails.
Figure 7: Overview of the status emails.
 Figure 8: Above, the unmodified monitored page; below the modified monitored page.
Figure 8: Above, the unmodified monitored page; below the modified monitored page.
HTTPie is a compact, well-rounded tool for data download and analysis. This article covers some of the basic functions. The other notes on the project page and on the man page are always a worthwhile read.
Infos